
Finding the right candidate or the right role starts with speaking the same language. In the real market that rarely happens. One company posts “Data Analyst,” another writes “Analista de datos,” someone lists “data analysis” on a profile and someone else adds “BI.” Wording shifts across languages, abbreviations and levels of detail. With this diversity it is easy for offers and candidates to miss each other and for decisions to take longer than they should.
ETHAN closes that gap with generative AI. We use LLMs to read job posts, LinkedIn profiles and course descriptions. We extract skills and occupations and normalize them to ESCO, the European standard. Once everything sits in a common taxonomy, you can compare like with like and build reliable indicators of what is in demand, where it is growing and how it changes over time.
How it works day to day
Automated mode runs as a pipeline that starts with ingestion. We pull job posts from our tracked sources and enrich them with metadata such as country, company and posting date. We also ingest training content so each course arrives with title, provider, language and a clean description. The ingestion stage deduplicates near copies, detects language and removes boilerplate such as legal disclaimers.
The extraction stage takes each clean text and asks an LLM to identify candidate skills and roles. Prompts are kept short and explicit, and the model returns a structured payload in JSON. We validate that payload against a schema so downstream steps never see unexpected fields. When the model finds compound skills like “data analysis with Python” we split them into atomic units so they align with ESCO definitions.
The normalization stage aligns every candidate to ESCO. We compute semantic candidates with embeddings and then apply a resolver that scores each option using similarity, exact alias matches and contextual hints from the original text. The resolver outputs the top ESCO code with a confidence score and a small set of alternatives. We keep thresholds for green, amber and red cases. Green flows through. Amber is flagged for quick review. Red is stored but excluded from aggregates by default.
All outputs are versioned and idempotent. If a source changes we reprocess and keep both the raw and normalized versions so time series remain reliable. The service runs on AWS so it scales without surprises while the API and the Streamlit interface stay stable as volume grows.
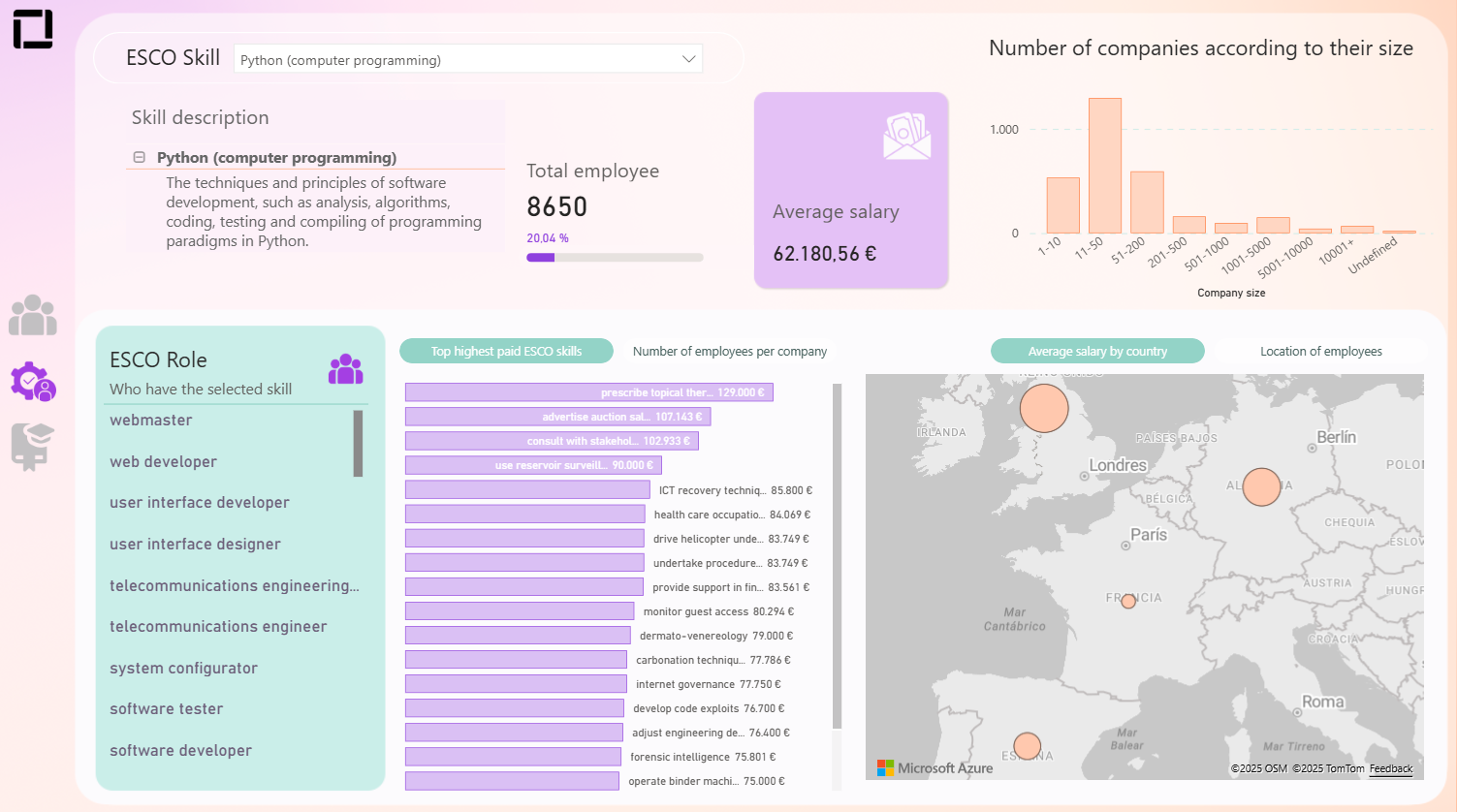
Interactive mode is for hands-on work. The Streamlit interface exposes the same endpoints the API provides. Paste a job post and you will see detected skills already mapped to ESCO with codes and confidence. Enter a single skill and you will get the closest ESCO match with near neighbors. Type a free-text title and you will receive the corresponding ESCO occupation. The interface also shows why a match was chosen by exposing the candidate list with scores, which helps when you tune thresholds for a new sector or language.
For developers there are two simple patterns. One takes free text and returns a list of skills with ESCO codes and confidence. The other takes a single skill or a single role and returns the best ESCO match plus alternatives. Responses are strict JSON so downstream systems can parse them without custom glue. Errors return structured messages with reasons such as unsupported language or text too short to classify. Rate limits and pagination are documented so batch use is predictable.

What data we cover
ETHAN currently works with job offers from Spain, France, Germany and the United Kingdom. It also integrates courses offered worldwide. This lets you connect what the market asks for with concrete training options, and compare signals across countries without losing consistency thanks to ESCO.
What it delivers in practice
Normalizing before analyzing cuts noise and speeds up decisions. Companies can filter and prioritize candidates with consistent criteria, run searches across several countries and direct upskilling toward what the market truly demands. Individuals benefit as well. If you are looking for a job, you can understand which skills you are missing for a given role and which courses best close that gap. If you want to strengthen your profile, you can see how your skills align with demand and what to learn next. By unifying the language, we remove the ambiguity and conflicting labels that make matching supply and demand so difficult.
Thanks to CDTI
ETHAN is part of an R&D project co-funded by CDTI. We include the plaque here for transparency and to acknowledge their support. If you want a demo or prefer to try the Streamlit interface with your own texts, let us know and we will set it up.



